
Introduction
In the Data Science team’s first blog, we reviewed our charter at Joveo. This week, we will discuss job embeddings at Joveo and how our Data Science team is leveraging state-of-the-art natural language processing (NLP) to address related challenges. Specifically, we will cover how to use SentenceBERT (SBERT) to establish meaningful vector representations for job postings. This covers the monolingual embedding space in the English language.
Every day, Joveo’s platform processes millions of job postings empowering the world’s smartest recruitment teams to showcase their job ads in front of the most relevant candidates. A job embedding is a machine-readable numerical representation of the job in an n-dimensional space, where job postings with the same semantic meaning have a similar vector representation. The primary requirement for such a representation space is that semantically similar job postings should be grouped together. For example, consider three job titles: “data scientist,” “machine learning engineer,” “mechanical engineer.” We want an embedding space that generates representations for these three titles, such that “data scientist” and “machine learning engineer” would be close together, while “mechanical engineer” is further away.
At Joveo, we use these job embeddings as a building block for many downstream applications and services, like occupation classification, job-to-job similarity, click and apply prediction, etc. In future blogs, we will be providing detailed explanations about specific downstream applications.
Joveo’s approach to Job Embeddings
Language models and data at Joveo
We take inspiration from the transformer architecture, that has been used as a building block for numerous pre-trained language models. The most well-known of these is BERT. These pre-trained language models can be visualized as a black box which encodes the syntactic and semantic structure of language(s) – much like the machine equivalent of a well-read human. These pre-trained models are then fine-tuned using a new dataset, to perform a task in the given language(s).
1. Suggested reading: Attention Is All You Need and The Illustrated Transformer
2. Suggested reading: BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding and The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning)
A typical inbound job listing at Joveo has the following structure:

So, in our use case, it makes more sense to compute embeddings for an entire sequence of text (e.g., sentences, paragraphs, etc.). The BERT network operates at an individual word level and does not provide an efficient way to compute embeddings for an entire sequence of text. To handle this challenge efficiently, in terms of reducing computing power and execution time for deriving sentence embeddings, we prefer SBERT. SBERT is an architecture that proposes the use of a Siamese or triplet network structure with two or three identical BERT-like models respectively to derive a fixed sized sentence embedding. Hence, it’s a prudent method to derive title and description embeddings for job postings at Joveo.
The challenge with the job postings data that we receive is that it is unlabeled and comes from a variety of sources and clients. This is precisely the reason why we need an embedding space to be able to understand, cluster, and categorize the jobs. Our goal is to generate intuitive and informative embeddings for these job titles and descriptions in a common representation space. To realize our goal, we fine-tune the SBERT model by feeding it text data – particularly from the job domains which are relevant for Joveo.
Since SBERT banks on sentence similarity based fine-tuning objectives, we need a dataset which contains job labels associated with the job titles and job descriptions so the model can learn similarity patterns between different job listings. For this purpose, we procured a proprietary dataset comprising more than half a million job listings, each tagged to one or more occupation class, based on standard ONET SOC taxonomy. The data which will be used to train the model uses the following structure:
3. Suggested reading: Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
Fine Tuning Sentence-BERT
For fine tuning, we picked a triplet objective, which uses a triplet network structure to minimize the distance between similar sentence pairs and maximize the distance between dissimilar sentence pairs. This help create an embedding space where jobs that belong to the same occupation class are closer to each other and jobs from different occupation classes are farther apart.
Training SBERT with this triplet loss function requires three data points as inputs to the network, namely an anchor (a) which is the given job description, a positive sentence (p) which is the associated job title of the job posting, and a negative sentence (n), which is the randomly sampled job title from a different ONET class. The above data points are transformed to form the triplet structure, as seen below.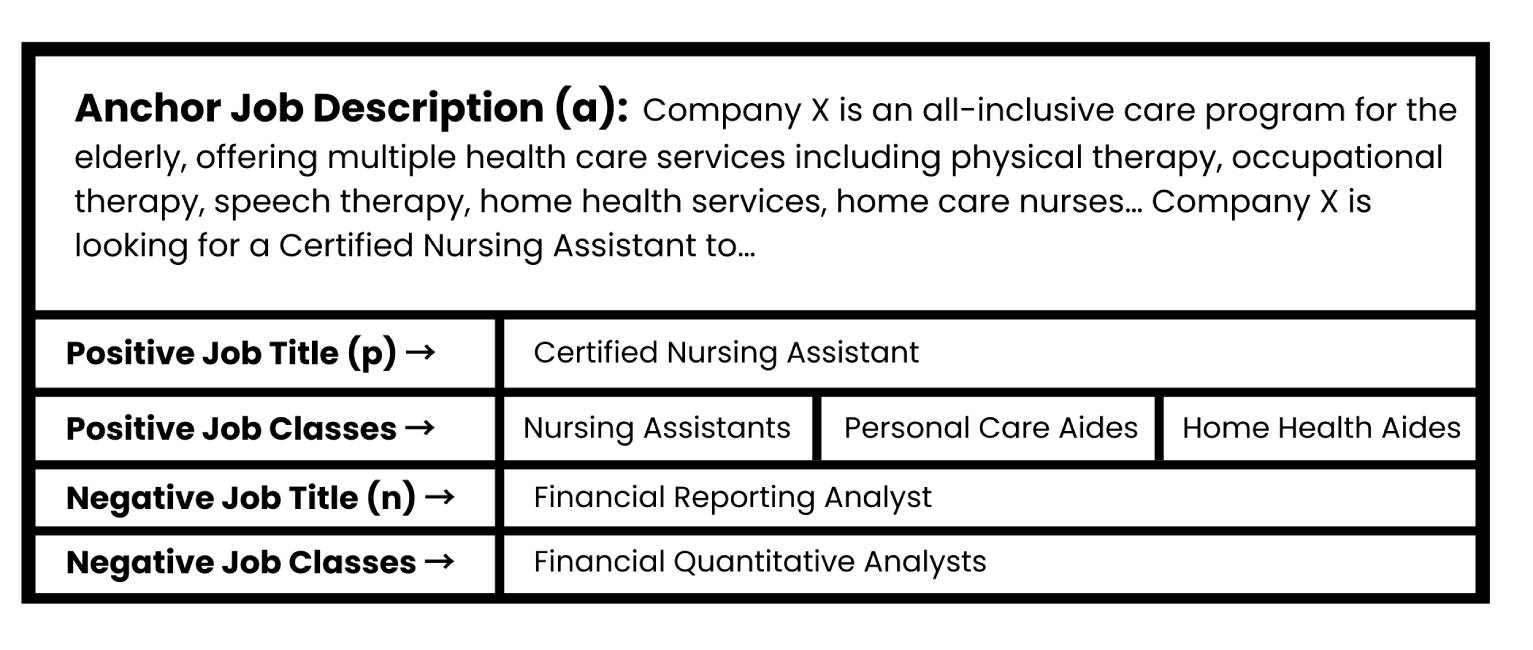
Basically, given anchor sentence a, positive sentence p, and negative sentence n, the triplet objective tunes the network so that the distance between a and p is smaller than the distance between a and n. Mathematically, it minimizes the following loss function:
max(||sa − sp|| − ||sa − sn|| + ε, 0)
With sx, the sentence embedding for a/n/p, || · || is a distance metric and ε is the margin which ensures that sp is at least ε closer to sa than sn.
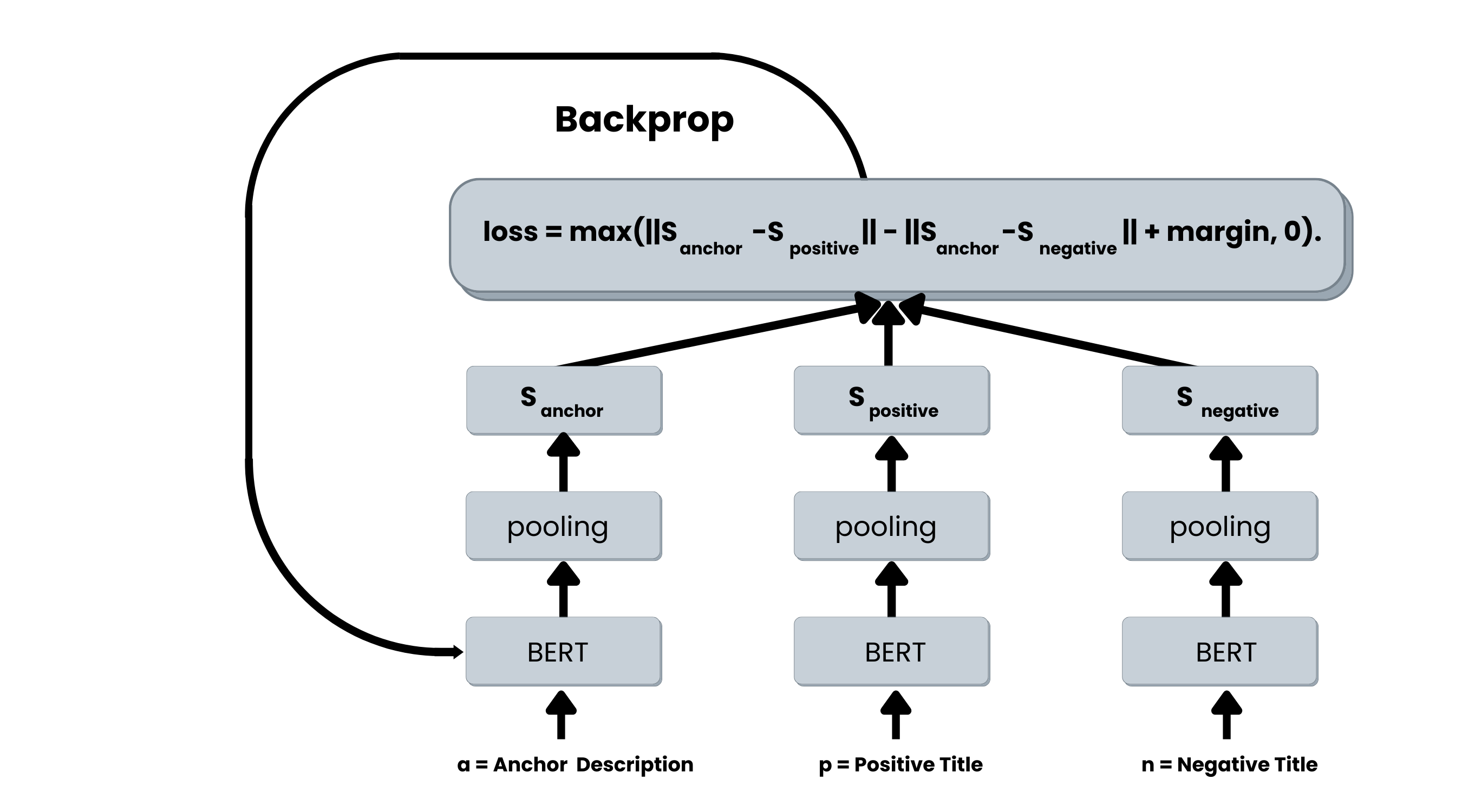
Figure: SBERT architecture with triplet objective function. The three BERT networks have tied weights (triplet network structure).
By feeding both title and description sequences from our dataset as separate triplet components to the triplet network, the model can create informative representations for both title and description individually. Based on our empirical observations, we have chosen RoBERTa as the base model to be fine-tuned using the SBERT architecture. You can choose any BERT-like base model (BERT, RoBERTa, DeBERTa, etc). For fine-tuning, we emulate this script from the sentence-transformer library. The process flow for fine-tuning is described in the following diagram:
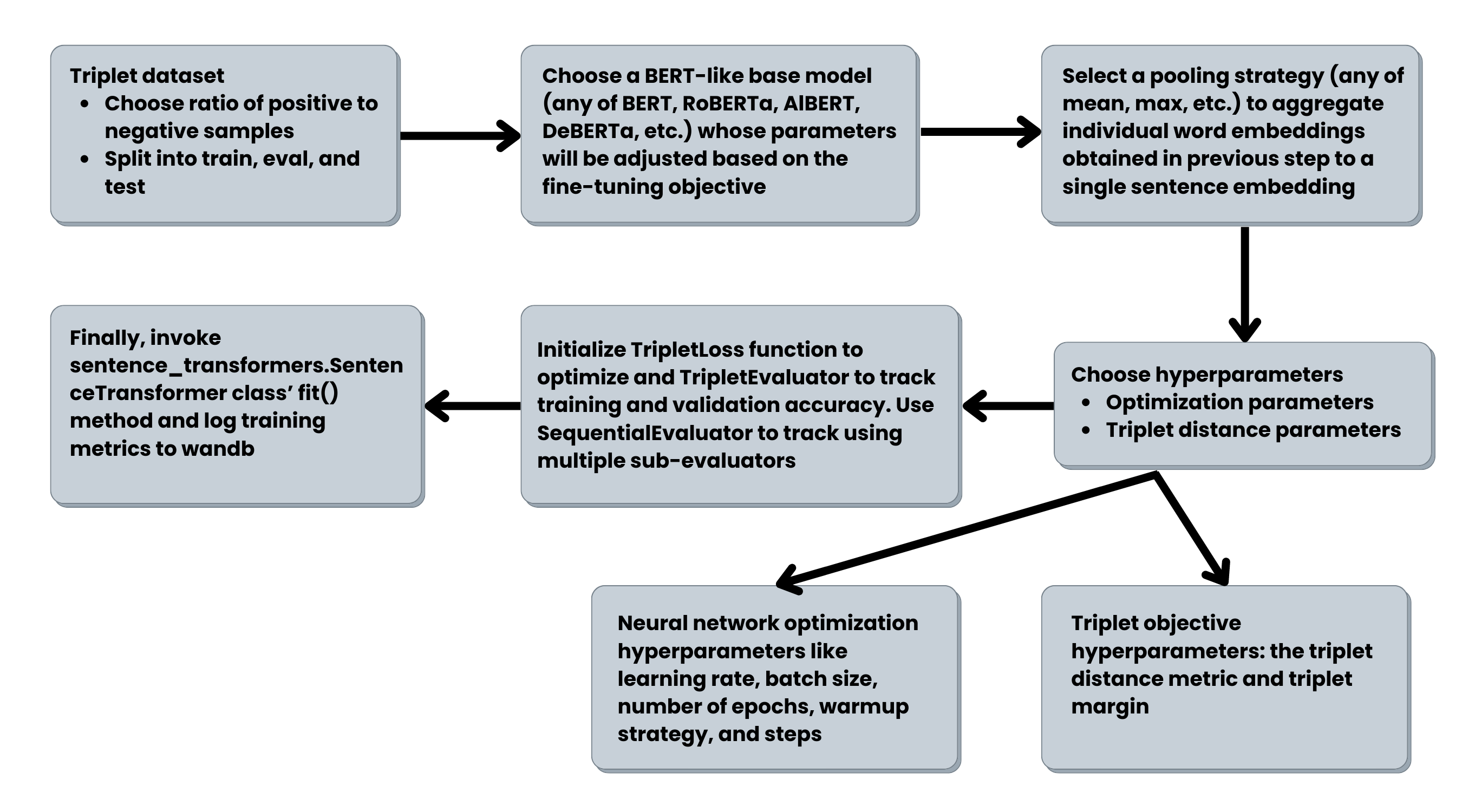
Evaluation of generated job embeddings
Now that we have fine-tuned the SBERT for our task, we will test the quality of the embeddings. For this, we need evaluators that can measure the semantic relationships amongst the jobs directly. After some research, we chose to detect outliers using compactness score for evaluating the embedding spaces.
Intuitively, the compactness score of a job in a cluster of jobs W = w1, w2, …, wn+1 is the average of all pairwise semantic similarities of the total jobs in W. The outlier is the job with the lowest compactness score in the given cluster. To formalize this evaluator mathematically, we take a set of jobs W = w1, w2, …, wn+1 where all but one job belong to the same class label. Hence, each cluster has n similar jobs and one outlier job. We then compute a compactness score of each job w ∈ W:
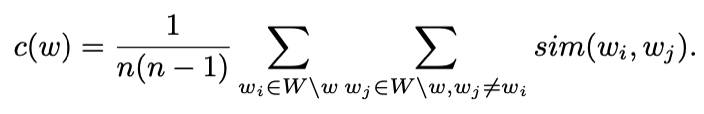
To establish whether the geometry of an embedding space is good, we measure the percentage of clusters in which the outlier is detected correctly. We have observed a significant lift of ~15% in outlier detection when comparing the SBERT fine-tuned embeddings with Joveo’s previous baseline word2vec embeddings. The figure below demonstrates an example of the fine-tuned SBERT embedding space producing better and more intuitive nearest neighbors, compared with baseline word2vec model for the job titled “Police Officer.”
4. Suggested reading: Evaluating Word Embedding Models: Methods and Experimental Results
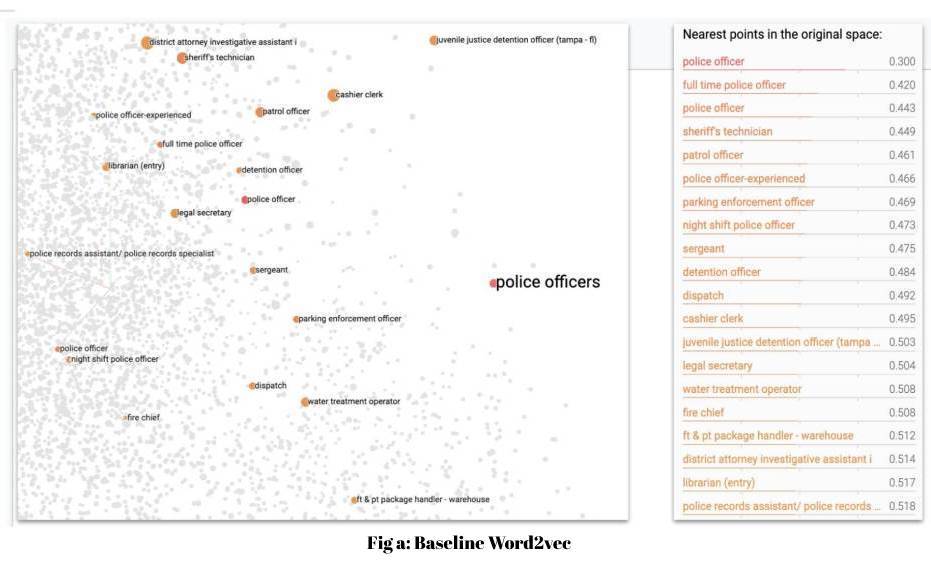
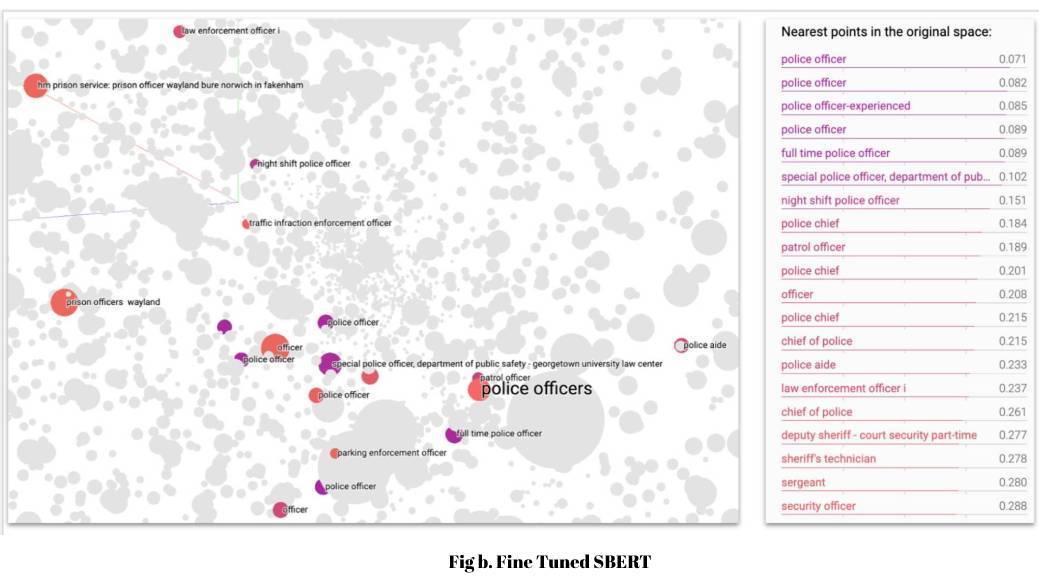
Nearest neighbors for “police officer” in embedding spaces
Conclusion
In this blog we demonstrated how to use SentenceBERT to obtain contextual and meaningful representations for job postings by generating the embeddings for both job titles and job descriptions independently. With this embedding space, we observed a significant lift in performance metrics over the previous baseline word2vec embeddings. This also translates to improved performance in downstream applications at Joveo, specifically occupation classification, job to job similarity, and click and apply prediction, amongst others.
Obtaining representations for jobs in the English language is the first step toward revamping jobs embedding spaces at Joveo. Since we cater to clients in multiple geographies, postings in multiple languages, we want to leverage this embedding model to build language-agnostic embedding spaces where the same job in different languages can be mapped to the same embedding.
The large size and high execution time of these huge neural network models demands that we find ways to further optimize using methods such as quantization, distillation, etc., to make them deployment ready.
Stay tuned as we proceed towards multilingual-izing, distilling and deploying our language models!














