
Summary –
Occupation classification uses machine learning to map job titles and descriptions to standardized codes like O*NET SOC. Joveo trained a custom SentenceBERT-based embedding model on half a million jobs, tackled issues like mis-labeled data and class imbalance, and improved accuracy across multiple languages and labels.
Introduction
Joveo is a programmatic job advertising platform that receives millions of job listings from a wide variety of employers every day. These employers can be job boards or direct employers that send direct job feeds to Joveo. However, each employer has their own way of categorizing jobs, which can be specific to their needs. For example, a job listing for an “AI Engineer” might be categorized as “ML Engineer,” “MLE,” “Data Scientist,” or “AI Engineer” by different companies, even though all of the job titles are for the same role and have the same responsibilities. Additionally, since Joveo has a presence across different countries, the inbound jobs are in a variety of languages, including English, French, German, etc.
For a given job, the job title alone doesn’t give the complete context. For example, the job title “First Line Supervisor” doesn’t provide complete information on the nature of the job. It can be “First Line Supervisor of Food Preparation and Serving Workers,” “First-Line Supervisors of Housekeeping and Janitorial Workers,” or “First-Line Supervisors of Non-Retail Sales Workers,” depending on the roles and responsibilities of the job. Hence it becomes important to have context before you can categorize a job to its relevant occupation. For this purpose, information in the job description is used along with the job title. Hence for the context of this blog, a job will consist of both the job title and the job description.
Joveo’s approach
To build a standardized occupation classification system, we require a standard taxonomy which is commonly used by our publishers (i.e job boards), where we advertise jobs. This taxonomy helps map the given job to its relevant standard occupation category, and act as labels for the underlying train or test data. We have used O*NET (Occupational Information Network) as the standard occupational classification (SOC) taxonomy which is developed under the sponsorship of the US Department of Labor/Employment and Training Administration. Because machine learning is being leveraged to solve this problem, we require job embeddings – machine-readable numerical representations of the job in an n-dimensional space, on top of which the occupation classifier will be built. Please refer to our last blog here, where we explain use of SentenceBERT to generate job embeddings for applications at Joveo.
Get your job ads in front of the right people, right place, right time… for the right price, with MOJO Pro – the only transparent programmatic platform. Spend 25% Less, Get 33% More Great-Fit Candidates
Implementation
Now that we have a standard taxonomy and a system to generate job embeddings, we will discuss how we built an accurate occupation classification model, the challenges we faced, and how we were able to overcome them.
Data is crucial for building any deep learning model. To train our model, we sourced approximately half a million data points from Joveo’s proprietary data and publicly available datasets from O*NET. The data is structured as input data which is the job (job titles, job descriptions) and corresponding possible ONET SOC codes as the output data or its ground truth.
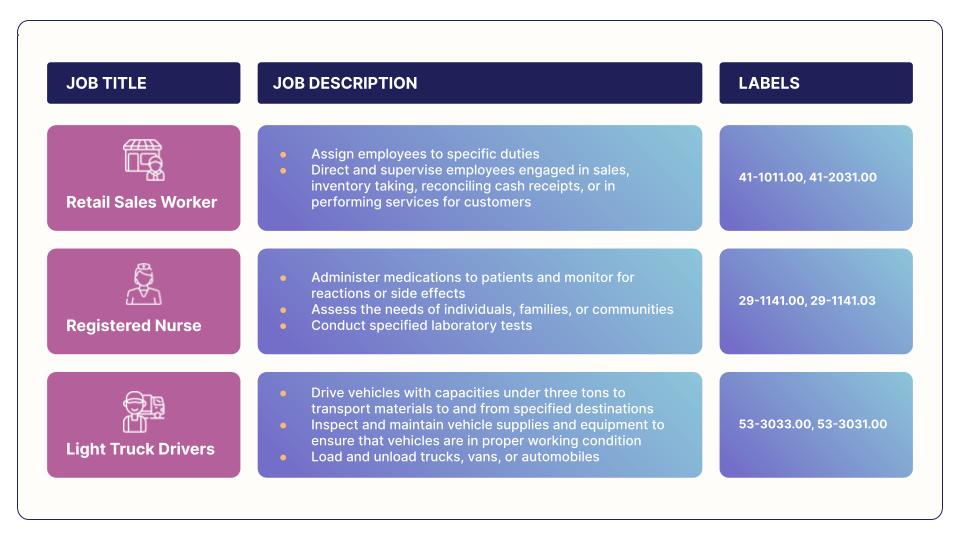
Note: mapping from SOC codes to titles can be found here
A job can fall into more than one O*NET SOC code, For example, “Truck Driver” can fall into heavy truck driver or light truck driver. Since a given input can have multiple output classes, we treat our problem as a multi-label classification problem. Even though we have enough data ready for modeling, the sourced data presented its own set of challenges.
- Presence of errors associated with labeling. For example, food delivery jobs tagged as light truck drivers
- Some classes are under-represented in training data – particularly for new-aged jobs, like block chain engineers, AI engineers, etc.
- Redundant information in job descriptions, like job id, job location (same description but different locations), etc., which do not provide additional value to the context for job classification
- Variety in terms of job languages for (English, German, French, etc.)
To mitigate these challenges, we leveraged the job embeddings model and Joveo’s in-house proprietary jobs collection.
- Identifying incorrect labels: To address labeling errors effectively, we implemented a strategy that utilizes cosine similarity to compare job titles with their corresponding SOC occupation titles and SOC alternate titles. For this we leveraged our pre-trained and fine-tuned SentenceBERT embeddings to calculate the cosine similarity. By setting a stringent threshold for similarity scores, we were able to accurately identify label mismatches and make the necessary modifications to generate resolved label data. This helped to resolve incorrect label mappings, such as “Data Scientist” under “Desktop Publishers” occupation to “Data Scientist” under “Data Scientist” occupation.
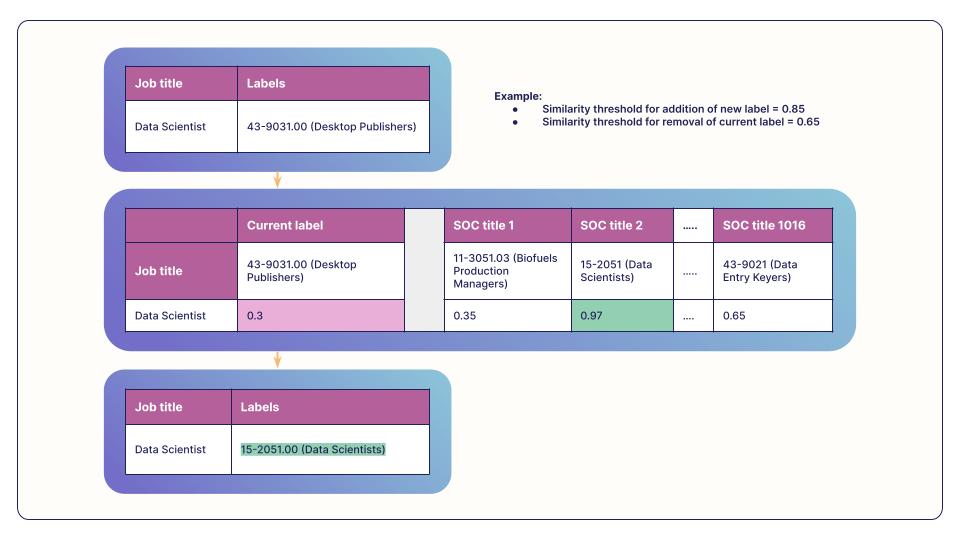
- Class imbalance: For the under-represented occupation classes in the training data, we pull similar other jobs from the Joveo’s in-house proprietary jobs collection using cosine similarity between SOC occupation title and under-represented job titles. This helped to balance the representation of different classes in the training data.
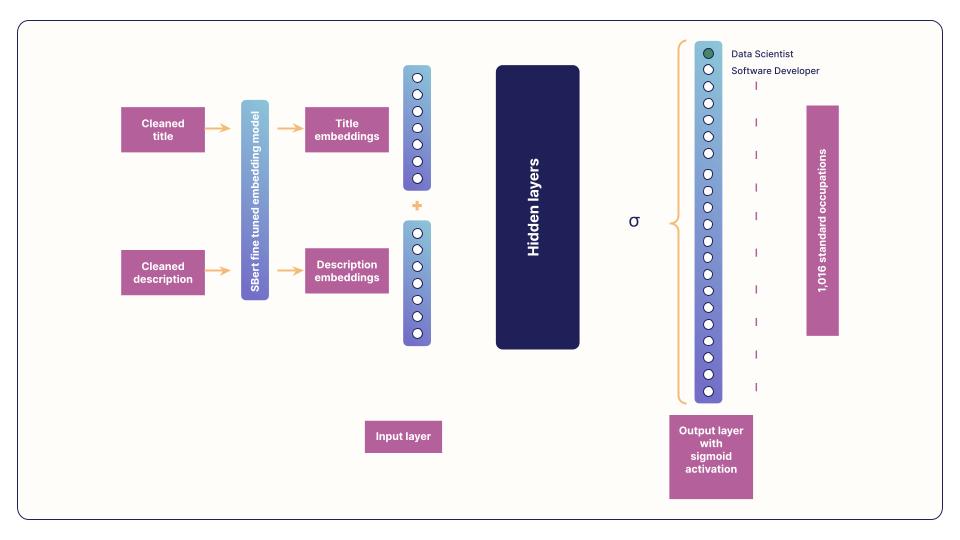
- After identifying and resolving label errors, we use entity recognition to obtain clean text, followed by embeddings creation. Recently, we achieved a significant breakthrough in building an in-house, language-agnostic embedding model (refer to this blog for more context). This model requires minimal text cleaning and produces intuitive and very accurate text embeddings.
By using this custom embedding model, we are able to vectorize job titles and descriptions for a job, resulting in two vectors (1x embedding size) for each title and description. These vectors are concatenated horizontally and passed to a feed-forward neural network as an input layer, which classifies the job to at least one of the 1,016 standard occupations.
Given that a job can fall into more than one O*NET SOC code, our model is designed to handle multiple output classes. Therefore, we treat our problem as multi-label classification, with sigmoid activation in the output layer. This allows us to accurately classify jobs to their corresponding standard occupations, even if they fall into multiple categories.
Even though numerous experiments were performed with varying type of models (SVM, Naive Bayes, Neural Nets), model architectures, type of embedding models (w2v, BERT-based, etc.), and degree of label error processing etc., neural networks trained on SentenceBert embeddings achieved the best model, which beats the incumbent Joveo occupation classification models by a comfortable margin. The best model was chosen based on top one-to-one accuracy and hamming score (done by exclusive or (XOR)) between the actual and predicted labels and then average across the dataset).
Conclusion
In this blog, we discussed Joveo’s approach to building a standardized occupation classification system, which involves leveraging machine learning and the use of O*NET as the standard occupational classification (SOC) taxonomy.
The process involved generating job embeddings using SentenceBERT and sourcing data from Joveo’s proprietary data and publicly available datasets. However, there were challenges, such as labeling errors and class imbalance, which were mitigated through the use of cosine similarity and Joveo’s in-house proprietary jobs collection.
By using entity recognition and custom embedding models, Joveo is able to vectorize job titles and descriptions and classify them to at least one of the 1,016 standard occupations. And, because the embeddings model is language agnostic we are able to cater to non-English languages like German, French, etc., as well. With this we observed a significant improvement in performance metrics over the previous baseline model.
All the hard work our data science team does just makes your life a little (a lot, really) easier! Request a demo today and see us in action. And don’t forget to follow us on Twitter and LinkedIn to see how Joveo can help you rock your talent sourcing goals.














